
tg-me.com/aihappens/351
Last Update:
Простите, был занят поездкой на чемпионат по Доте в Копенгагене и не рассказал вам про новую модель от OpenAI — O1.
Начнем с простого — нейминг снова в говне ужасный. (Найдите разницу — 4о и O1. Дальше предлагаю модель О_о назвать ☺️.)
Теперь по существу. Что вообще изменилось в модели?
По сути, они реализуют механики, которые всегда советуют для получения крутых ответов на сложные вопросы: разбивка задачи на этапы, продумывание и критика решений на этих этапах. Всё это можно было делать и раньше, но никто в здравом уме в повседневной жизни так не писал промпты. Сейчас это будет удобной опцией, ну и собственно, отличие в том, что модель за вас продумывает эти шаги между этапами.
Почему метрики у модели на обычных задачах почти не выросли?
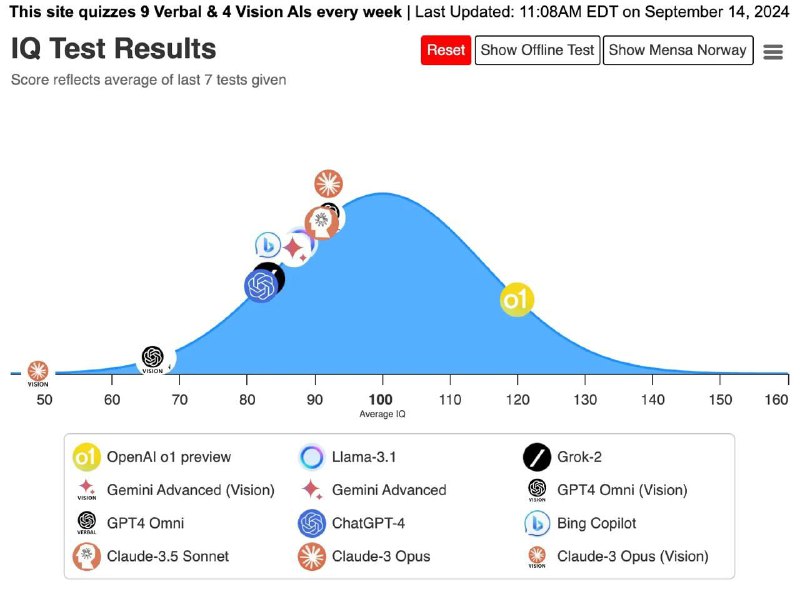
Потому что во всех бенчмарках модели и так запускались в режимах CoT ( и т. д., что значит, что это делали вручную исследователи — запускали модели 20 раз, заставляя рассуждать и давая примеры решений аналогичных задач.) Но ситуация абсолютно иная на логических задачах — там, где люди всегда хихикали над задачами на образное мышление или скрытые смыслы. Хлобысь — и модель уже на уровне олимпиадников по математике в этих задачах. Это подтверждается интересным тестом с картинки, где модель проходит тесты на IQ. (Для справки, тесты на IQ построены так, что 100 = медиана среди всех людей.)
Повлияет ли это на обычных пользователей?
Почти уверен, что нет. Это релиз, в моем понимании, направленный на исследователей в широком смысле этого слова. У них появился шанс с большей вероятностью найти идеи для решения своей задачи в голове GPT.
@aihappens
BY AI Happens
Share with your friend now:
tg-me.com/aihappens/351